实验设计
科学涉及到对不同变量之间关系的探索。在心理学研究中,研究者常常采用以下几种方法来研究变量间的关系:
1. 相关研究
相关研究即观察在自然情境中存在的两个变量,是寻求变量之间关系的最简单的方法。相关研究只能够说明两个变量之间的相关程度,却不能提供因果关系的证据。如果想要进一步研究因果关系,则需要进行实验研究。
2. 实验研究
实验研究的目的是为了确定两个变量之间的因果关系,即一个变量的变化是不是由另外一个变量的变化引起的。实验研究一般具有两个特征:①研究者需要操纵一个变量,然后观察另外一个变量,看这种操纵是否带来了变化:②要对研究中的其他一些无关变量进行控制,以确保这些变量不会对研究的结果产生影响。
3. 准实验研究
准实验研究是介于真实验研究和非实验研究之间的一种研究,它对无关变量的控制好于非实验研究,但它又不没有真实验研究控制得那么充分和严格。在准实验研究中,自变量是一些研究者无法控制的、自然存在的因素,研究者考查已有的各组被试间的差别或在不同时间内采集的数据的差异。
4.非实验研究
非实验研究比准实验研究在控制的严格性上弱一些,一般用于考查自然存在的变量之间的关系,这是一种对现象的描述。常见的方法有观察法、问卷法等。
(二)科学方法
在心理学乃至大部分科学研究中,理论和假设是两个不可或缺的概念。心理学理论是对行为的潜在机制的一系列陈述,它可以用来解释心理学各个领域中的问题。假设是针对每次研究更加具体的一种预测,它会提出不同变量之间可能的关系。事实上,研究就是要来验证某假设正确与否。当研究的结果与其假设相符,那么假设成立,原来的理论得到加强或补充:如果研究的结果与其假设背道而驰,那么假设被推翻研究者需要将这个新的发现填充到理论中,对理论进行修订,然后从中得到一个新的假设,继续进行研究。
(一)总体、样本和随机取样
1. 总体
总体是指具有某些共同的、可观测特征的一类事物的全体,构成总体的每个基本单元称为个体。在心理学研究中,总体是特定研究所关注的所有个体的集合,研究者一般根据研究的兴趣和目的规定研究的总体,其特征和范围也随着目的和要求的变化而不同。总体既可以是有限的也可以是无限的
2. 样本
样本是从总体中抽取的作为真正的研究对象的一些个体的集合。从总体中抽取的样本有大有小,一般来说要依据研究的目的而定。
3. 随机取样
随机取样是指从总体抽取样本的一种策略,要求总体中的每一个个体被抽到的机会均等。只有对总体的分布、特征等有了全面的认识,才可能选取恰当的随机取样方法,保证所抽取的样本在最大可能上具有同总体一致的分布和特征,达到采取随即方法所希望的。
1. 描述统计
描述统计是指用来整理、概括、简化数据的统计方法侧重于描述一组数据的全貌,表达一件事物的性质。描述数据集中趋势的最常用的是求平均值,描述数据的离散情况最常用的是标准差。描述统计常常利用图、表的方式来表示,给研究者一个直观的对数据的整体认识。
2. 推论统计
推论统计是指运用一系列的数学方法,将从样本数据中获得的结果推广到样本所在的总体。进行推论统计的关键在于所抽取的样本要能够尽量接近所要研究的总体,能够充分代表总体,使得用样本中的信息来推论总体时产生的误差最小
1. 参数与统计量
参数是描述总体的数值。它既可以从一次测量中获得也可以从总体的一系列测量中推论得到。统计量是描述样本的数值。它可以从一次测量中获得,或者从样本的一系列测量中推论得到。参数是一个固定的数值,而统计量的值是不定的,它会随着所取的样本而变化。
2. 取样误差
取样误差是指样本统计量与相应的总体参数之间的差。影响取样误差的因素有很多,包括样本容量、总体的变异情况、取样方式等。取样误差是难以完全避免的,研究者要做的就是尽可能减少取样中的误差,并使之保持在研究所允许的范围内。
1. 离散型变量
离散型变量是由分离的、不可分割的范畴组成,在邻近范畴之间没有值存在。比较有代表性的离散型变量是计数数字。
2. 连续型变量
连续型变量指在任何两个观测值之间都存在无限多个可能值,它可以分割成无限多个组成部分。一般来说,一个连续型变量可以用一条连续的实数直线表示,在实数直线上存在着无限的点,在任何两个相邻的点之间依然可以找到无数个点。
变量的测度等级
按照概念被量化的程度,变量的测度等级通常可以分为以下四类:
1. 命名测度
命名测度是最低的一种测度等级,由一系列具有不同名称的类型所组成。命名等级的度量对观察所得的数据进行标定并分类,它只包含质性差异,不能提供任何有关量的差异的信息。
2. 顺序测度
顺序测度的量化水平高于命名等级,是由一系列按顺序排列的范畴所组成。也就是说,观察得到的结果不但分了类别,而且还是按照一定顺序进行排列的。顺序等级可以提供不同个体之间的顺序差异,然而不能够说明这种差异的程度和大小
3. 等距测度
等距测度是量化水平更高,是由一系列按顺序排列的范畴组成,且每两个邻近范畴之间的距离都相等。等距等级采用一定单位的实际测量值,可以进行加减法运算,但是不能进行乘除法运算。
4. 比例测度
比例测度是最高的测度等级,除了具有等距测度的所有特征外,还有绝对零点。比例等级的变量除了可以进行加减运算,还可以进行乘除运算。
次数分布是指一批数据在某一量度的每一个类目所出现的次数情况。在统计中,得到次数分布的方法是将原本没有组织的数据从高到低进行排列,将相同值的数据归并在一组。在具体的表示形式上,次数分布可以表达为图或者表的形式。
1. 直方图
直方图是指用横轴表示数据X,纵轴表示次数f,以一些画在每个数据之上的直方条来表示次数分布,直方条的高度代表了各个数据的次数,宽度代表数据的精确区间。只有数据是等距或等比量度时,才能用直方图。
2. 棒图
当数据是命名或顺序量度时,用棒图来表示次数分布。棒图与直方图类似,也是用一些直方条画在每个分数之上来表示次数分布,不同的是棒图在每个直方条之间有一段空间,而不是紧挨着的。
(二)折线图
折线图又称次数分布多边图,它与直方图的绘制方法类似,不同的是折线图不是以直方条的高度代表次数,而是将每个X值对应的次数点相连成折线。折线图适用于等距或等比型数据。折线图以线的曲折表示了数据的变化趋势,这是直方图和棒图所不及的。在用折线图表示分组次数分布表时,每一个点的横坐标是每个分组的中间值,纵坐标是该组包含的数据个数。
(三)茎叶图
1977年,J.W.
Tukey发明了茎叶图,弥补了次数分布表过于简明扼要的缺陷。在茎叶图中,每个分数被分为两部分:第一位数字作为“茎”,第二位数字作为“叶”。“茎”一栏的数值对应于分组区间,每个“茎”右边的“叶”的数量则代表了与“茎”相对应区间内的次数。茎叶图不仅列出了所有的数据,而且没有丧失次数分布图所拥有的直观特性。在正式的报告中,一般不列出茎叶图,而是使用传统的次数分布表或次数分布图,因此最好将茎叶图视为一种对数据进行初步整理的方法。
集中量数
集中量数又称集中趋势,是体现一组数据一般水平的统计量。它能反映频数分布中大量数据向某一点集中的情况
(一)算术平均数
1. 含义
算术平均数(mean)是最常用的,也是最容易理解的一个集中量数指标。算术平均数是所有观察值的总和与总频数之商,也简称为平均数、均值或者均数。可以用
来表示;如果想表示变量X的平均数,可以表示为 。
(二)中数
中数(median)又称为中位数,它将数据分为数目相等的两半,其中一半的值比它小,另外一半的值比它大,等价于百分位数是50的那个数。如果将所有数据按照大小顺序进行排列,那么中数正好位于正中间中数用M表示。对于一个分布而言,中数将其分为大小相同的两个组。对于没有经过处理的原始数据,需要先将所有数据按照大小顺序排成一个数列。
(三)众数
众数(mode)是指出现次数最多的那个数或类目,用M来表示。需要注意的是,众数有可能不止一个。
差异量数是对分布的延伸和聚集状态程度的定量化描述。差异量数越大,表示数据间的差别越大;差异量数越小,表明分数间越近似。常用的差异量数包括全距、标准差和四分差等
全距
全距也称为极差,指数据中最大值与最小值之差用符号R表示。全距小表示数据比较集中,全距大则表示数据比较分散。全距是一个大致的、粗略的差异量数,一般只被用于预备性检查,用来了解数据大概的分布情况,确定分组的方法。R为数据中的最大值和最小值的差值。
标准差
标准差是一种最重要也是最常用的差异量数,它描述了分布中的每一个个体与某一标准之间的距离。标准差将分布中的所有信息都考虑在内。
总体的方差和标准差
(1)总体的方差
总体的方差是指和方除以总体容量所得出的数值,用公式表示: 。
总体方差实际上就是离差平方的平均值,也被称做均方。方差的本质是对距离的平方的一种量度。
(2)总体的标准差
总体的标准差是指总体方差的平方根,其公式为
计算总体标准差的步骤:① 计算出和方SS:② 用SS除以容量N确定方差;③
取方差的平方根确定标准差。推论统计中,方差是一个很有价值的量数。但是,在描述数据的差异性方面,标准差比方差更为有用因为标准差和离差处于同一数量级别,是对距离的一种量度。
3. 样本的方差和标准差
推论统计的目标是利
自由度
自由度是指可自由变化的数值的个数。也可用符号df表示,其值为n-1。由于其均值是确定的,在一个样本的分布中,固定了前n-1个分数,最后一个分数也就被固定了。
差异系数
差异系数是一组数据的标准差与平均数的比率,用符号CV表示。CV属于相对差异量数,不具有测量单位。差异系数越大,表示离散程度越大。
z分数的含义
z分数由正负符号和数值两部分组成。符号的正负表示出了z分数所对应的原始分数比均值大还是小,正号表示分数比均值大,负号表示比均值小;z分数的数值表示的是原始分数和均值之间相差几个标准差,即以标准差的个数表示出原始分数和均值之的距离。
二、正态分布
含义
概率就是指从某个总体中得到特定的样本的可能性。在某种情景下,可能得到各种不同的结果。在心理学统计中,它是联系总体和样本的一条纽带。假设可能出现的结果有甲、乙、丙、丁等等,那么出现甲结果的概率被定义为:甲的概率=出现甲结果的数目/可能出现的结果的数目
1. 简单随机取样
简单随机抽样是最基本的一种随机取样方法,具体操作是可以将总体中的每一个个体都编上号码并抽签,或者利用随机数字表。这种抽样只适用于总体数目较少且总体的个体之间差异程度较小的情况。
2. 等距抽样
当总体的数目非常大时,可以使用等距抽样,也是将每个个体编号,并且将已编好号码的个体排成顺序,然后每隔若干个抽取一个。一旦定下取样间隔和起点之后,每一个个体就没有相等的机会被抽取到,而是只有每隔一定的间隔的个体才能被抽取。但是这个方法使得被抽取的个体均匀地分配在总体当中,而不会发生聚堆的现象但是,不适合总体排列具有周期性的情况。
3. 分层随机抽样
当总体内的个体差异比较大时,必须考虑到总体的这种信息再进行随机抽取。在抽样时先根据差异分成不同的层次,然后再在每个层次中随机抽取。在进行分层随机抽样时,每一层中抽取的样本数目可以不同,更恰当的方法是应当考虑总体的比例。
4. 阶段抽样
当总体容量很大时,直接以总体中的所有个体为对象进行抽样,在实际调查或研究中存在很大困难。此时,对于这种大范围的调查研究一般采取阶段抽样方法,如两阶段随机抽样首先将总体分成M个部分,每一部分是一“集团”(“群”),第一步从M个集团中随机抽取m个作为第一阶段的样本,第二步是分别从所选取的m个“集团”中抽取n个个体构成第二阶段样本。
取样分布
取样分布是指从同一总体中可以抽取出很多个样本,总体中可抽取的所有可能的特定容量分布的统计量(包括平均数,两平均数之差,方差,标准差,相关系数,回归系数,百分比率等等)所形成的统计分布。
2. 取样分布与总体分布的区别
取样分布是参数或统计量的集合,而总体分布和样本分布则是原始分数的集合。
样本均值分布
1. 含义
样本均值的分布是取样分布的一个特例。它是指总体中可抽取的所有可能的特定容量(n)的随机样本的均值的集合。样本均值的分布包含所有可能的样本由于属于取样分布,在样本均值的分布中,值不是分数,而是统计量(样本均值)。
2 中心极限定律
对于任何均值为 ,标准差为 σ 的总体,样本容量为n的样本均值的分布,随着n趋近无穷大时,会趋近均值为 ,标准差为 的正态分布。因此,当n足够大时(30或以上),近似地有
。中心极限定律综合了样本均值的形状、均值和方差这三个特征。
标准差、标准误和取样误差
1. 标准差:标准差是总体中的概念,指的是总体中一个分数与总体均值的标准距离,衡量的是次数分布的变异性。
2. 标准误:标准误是样本均值分布中的概念,是指一个样本均值和其相应的总体均值之间的标准距离,衡量的是样本均值分布的变异性。
3. 取样误差
(1)取样误差描述了样本和总体所得到的统计量与参数之间的偏差(或误差)。任何一个样本均值可能大于或小于总体均值。
(2)标准误则提供了一个衡量取样误差的方法。它衡量了样本均值与总体均值之间平均差异,这样就可以知道样本能在多大程度上代表总体。
(3)可以把标准差看成是标准误的特例。标准误的公式 = ,如果是一个单个分数,即n=1,那么 ,即标准误等于标准差。
一、假设检验的性质和种类
(一)假设检验的性质
假设检验是一套利用样本数据来评价关于目标总体的某一假设的可置信性的推断程序。其实质是对可置信性的评价。可置信性是指在多大程度上可以相信这个假设是正确的。假设检验程度的判断是基于样本均值的概率分布的。
假设检验并不是对假设的正确性做出确定的判断,而是对一个不确定问题的决策过程(判断),其结果从概率上很可能是正确的,但是不排除错误的可能性。假设检验只是一种统计方法,而不是真理
二、假设检验的基本逻辑
(一)两种假设
1. 虚无假设,用H0表示,意为研究者所预期的改变、差异、处理效果都不存在。
2. 备择假设,用H1表示,表明因变量的变化或者差异确实是由于自变量的作用,一般也是研究者对于研究结果的预期。
(二)决策标准
在任何计算步骤进行之前,首先必须明确规定决策标准,即显著性水平(即α水平)。在检验过程中,假设H0为真实的,同时计算出所观测到的差异完全是由于随机误差所致的概率,称为观测概率p。将p和事先界定好的显著性水平α进行比较,从而对虚无假设H0得出结论
(三)考验统计量
z分数能够表示样本均值在目标总体的样本均值分布中的相对位置的一种统计量。它不仅考虑了样本均值与总体均值的差异,同时也考虑了总体的均值和样本容量。将代表显著性α水平的那个临界值转化成临界z分数(记做zcrit),然后将根据样本均值所计算出的实际z分数(记做zobs)与之进行比较,从而作出结论常用的显著性。水平α=0.05的双尾检验中样本均值和z分数的对应,其中临界z分数为±1.96。但是,z分数的使用要求总体的方差已知。
四、假设检验的两类错误
(一)Ⅰ类错误与Ⅱ类错误
1. 第一类(Ⅰ类)错误
(1)含义:第一类错误也称
α错误,是指当虚无假设正确时,拒绝了H0所犯的错误。这意味着研究者得出了处理有效果的结论,而实际上并没有效果,即观察到了实际上并不存在的处理效应,形象地说便是“无中生有”。
2. 第二类(Ⅱ类)错误
(1)含义:第二类(Ⅱ类)错误也称
β错误,是指当虚无假设错误时接受H0所犯的错误。这意味着假设检验未能侦察到实际存在的处理效应。犯Ⅱ类错误所造成的后果没有1类错误严重,如果研究者对自己的假设很有信心,或者有较强的理论支持,往往会另外抽样重复实验,或是对实验程序进行改进,从而证明处理效应是存在的。
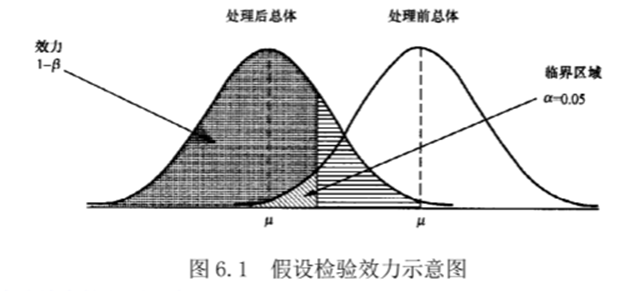
六、假设检验的效力
(一)效力
假设检验的效力是指该检验能够正确地拒绝一个错误的虚无假设的概率,因此效力可以表示为
power=1-β,效力反映了假设检验能够正确侦察到真实的处理效应的能力。检验的效力越高,侦察能力越强
图6.1直观地展示了效力大小以及与临界区域的关系。如果均值落在了阴影区域,即处于临界区域,则拒绝虚无假设,认为该样本来自另外一个总体。即样本均值落在阴影区域的时候,正确拒绝了错误的虚无假设。因此阴影区域即表示假设检验的效力,如果样本均值落在了旁边的横条纹区域,则不能拒绝虚无假设,假设检验没能够侦察到实际存在的处理效应,也就是Ⅱ类错误。因此,横条纹区域实际上代表了Ⅱ类错误的概率。
一、参数估计与假设检验
1. 估计与参数估计
估计是指为了获得一个具体情况未知总体的情况,人们调查了总体的一个部分(样本),并根据这个调查对未知的总体的情况进行猜测。这种通过样本对总体的参数进行猜测的统计推断方法。参数估计回答的问题是总体的参数是多少,或两个总体的差异有多大。通过参数估计,将得到一个数值(点估计)或一个区间(区间估计)来表示未知的总体的参数或参数可能的变化范围。
(一)点估计的概念
点估计,就是用单一数值对总体的未知参数进行估计。如用样本的均值估计总体均值,用样本方差估计总体方差等等。
(一)区间估计的概念
1. 区间估计
(1)概念:区间估计是指用一个区间以及这个区间覆盖总体未知参数的概率的估计方法,这个区间称为置信区间(CI),相对应的概率称为置信度(1-α)(或置信系数)。
因素
在方差分析中,一般用来做比较组的变量被称为因素
水平
组成一个因素的数值或条件被称为这个因素的水平
1. 方差分析的概念
方差分析(又称为变异数分析)ANOVA,由英国统计学家 Ronald
Fisher发展而来的,方差分析中的关键步骤F检验也是用他的名字命名的。方差分析能够解决简单的t检验,z检验不能解决的问题,对实验设计和统计分析的发展起到了巨大的推动作用。
二、事后检验
1. 含义
ANOVA的结果是检验H0:μ1=μ2=μ3,只知道一些组与其他组不同,但并知道差别在哪些组之间。所以从
ANOVA得到显著差异的结果(拒绝H0)后,一定要做作事后检验。事后检验就是比较每一个处理组与另一个处理组,一次比较两个,这称为成对比较。
常用的事后检验有:HSD 要求所有的样本容量相同,比较敏感;Scheffe检验适用于每组样本数不同的情况,比较保守,最大限度地降低了 α;方差不齐的时候则使用 Tamhane
T2。
(一)主效应
自变量的主效应是指某个自变量的不同水平对因变量所造成的影响的差异。
(二)交互作用
交互作用是指在多因素的方差分析中,一个因素对因变量的影响因另一个因素的不同水平而不同的现象。因素之间彼此是否独立决定了交互作用的产生。如果两个因素彼此独立,即不管其中一个因素处于哪个水平,另一个因素的不同水平均值间的差异都保持一致,则不产生交互作用:反之,如果两个因素彼此不独立,即当其中一个因素处于不同的水平时,另一个因素对因变量的影响不同时,便出现了交互作用。
简单主效应:在A水平的某个水平上因素B的不同水平均值的差异。把检验得到的显著结果称之为因素B在因素A该水平上的简单主效应
一、相关
(一)概念
相关描述的是双变量数据之间的关系。
一般来说,事物之间有三种关系:① 因果关系, 即一种现象是另一种现象的原因;②
共变关系,即表面上看起来有联系的两种事物都与第三种现象有关;③相关关系,事物之间存在联系但又无法确定是因果关系或共变关系。
相关的类别有三种:① 正相关,即两个变量变动方向相同,同增同减;② 负相关,即两个变量变动方向相反,一增一减或一减一增;③
零相关,即两个变量之间没有联系,一个变量变动时,另一个变量做无规律变动。
(三)散点图
在直角坐标系里,以X、Y二列变量的一列变量为横坐标,以另一列变量为纵坐标,把每对数据当成一个平面上的点,一一描绘在该坐标系中,产生的图形就称为散点图。散点图通过点的散布形状和疏密程度来显示两个变量的相关趋势和相关程度,能够对原始数据间的关系做出直观而有效的预测和解释。若散点图呈左低右高的椭圆形表明两列变量呈正相关;若散点图呈左高右低的椭圆形表明两列变量呈负相关;若散点图的分布呈正圆形,则表明两列变量之间没有线性关系。
二、回归
(一)回归分析概述
1. 回归分析的含义
回归分析是通过大量的观测发现变量之间存在的统计规律性,并用一定的数学模型表示变量相关关系的方法。当只有一个自变量并且统计量成一次函数的线性关系的回归分析叫一元线性回归分析。
二、参数检验和非参数检验
1. 参数检验
参数检验中,总体的分布形式是给定的或是假定的,只是其中一些参数的取值或范围未知,分析的主要目的是估计参数的取值,或对其进行某种统计检验。参数检验的共同前提是总体是正态分布;如果检验涉及两个总体,两总体须方差同质。
2. 非参数检验
非参数检验对总体的分布情况要求低,也不要求对总体的参数进行假设,在参数检验的假设无法满足时,可以运用非参数检验。非参数检验也称为分布不限定检验。
三、卡方检验
卡方检验的基本原理
卡方检验适用于心理研究中的计数数据,是一种非参数的检验方法。卡方检验的方法能够处理一个因素两项或多项分类的实际观察频数与理论频数是否相一致的问题,或说有无显著差异的问题。
实际频数是指在实验或调查中得到的计算资料又称观察频数理论次数是指根据概率原理、某种理论、某种理论次数分布或经验分布计算出来的次数,又称期望次数
(一)多元回归方程的概念及原理
1. 多元回归方程的概念
多元回归分析是一种用于评价一个因变量和多个自变量之间关系的统计技术,其数学模型如下:
该公式表示n个自变量共同作用于因变量y,常数项c为方程在y轴上的截距,b是第n个自变量x的回归系数,它表示的是在其他自变量不变的情况下,自变量x每变动一个单位所引起的因变量的变化,因此,回归系数的绝对值越大,表明该自变量对因变量的影响越大:e表示误差项,即观察不到的可能对因变量造成影响的因素。
(一)因素分析的概念
在实际的研究中,面对很多的观测变量,经常需要把它们进行浓缩,找出数据之间的内在联系,以最少的信息丢失为代价将众多彼此之间可能有关系的观测变量浓缩为少数几个因素。这种将一系列变量归结为较少变量,以揭示其潜在结构的统计程序就是因素分析。
(二)因素分析的种类
因素分析按照研究者对因素的确定性程度可以分为两类:探索性因素分析(EFA)和验证性因素分析(CFA)。
1. 探索性因素分析
在探索性因素分析中,研究者事先对观测数据背后可以提取出多少个因素并不确定,因素分析主要是用来探索因素的个数,所以被称为探索性的因素分析。
2. 验证性因素分析
在验证性因素分析中,研究者根据已有的理论模型对因素的个数,以及每个变量在哪个因素上有载荷有明确的假设,所以这时的因素分析主要目的在于对假设进行验证。
注意两者并不是完全对立的,在实际应用中。可以发现一个好的研究往往不单纯用探索性因素分析,而是以探索性因素分析开始,以验证性因素分析结束。
